
CONOZCA LOS PASOS DE LA METODOLOGÍA DE MAPBIOMAS
Aquí detallamos la metodología de MapBiomas paso a paso. Para cada clase y tema tratado en el mapa existen características específicas que se pueden consultar en detalle en el ATBD (Documento Base Teórico de Algoritmos) y sus anexos.
DESCARGAR LA METODOLOGÍA COMPLETA – ATBD
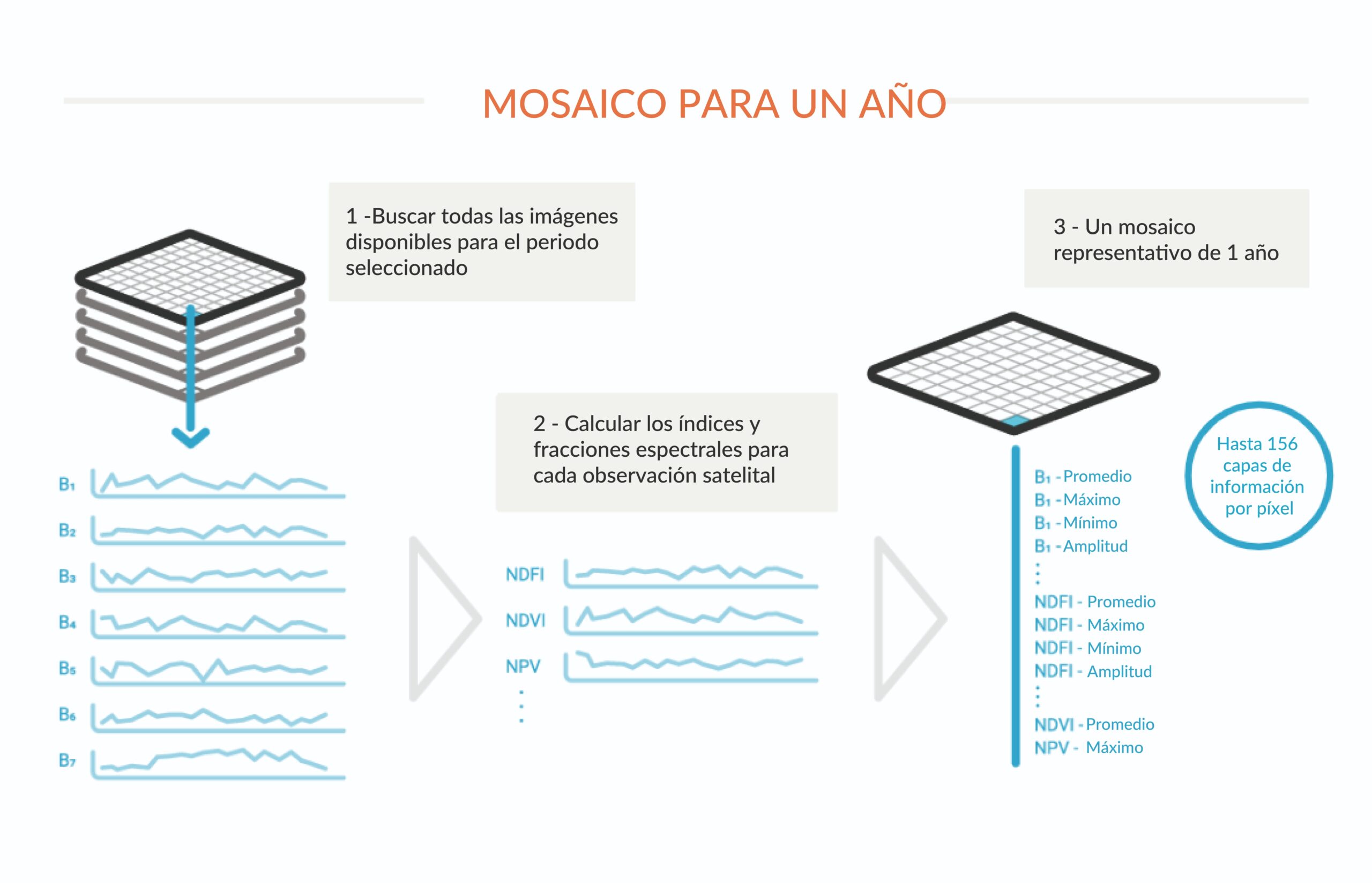
Todo comienza con imágenes del satélite Landsat, con resolución de 30 metros, disponibles de forma gratuita en la plataforma Google Earth Engine y con una serie temporal de 39 años. Se construyeron 16.418 mosaicos en todo el límite RAISG, cada uno con decenas de millones de píxeles en total. Estos píxeles son las unidades de trabajo de MapBiomas. Las imágenes pueden contener nubes, bruma y otras condiciones que pueden afectar su calidad. Para producir una imagen limpia se seleccionan los píxeles despejados de las imágenes disponibles para el período seleccionado. Para cada uno de estos píxeles se extraen métricas que explican el comportamiento del píxel en ese año. Esto se hace con cada una de las 7 bandas espectrales del satélite, así como con las fracciones e índices espectrales calculados. Por ejemplo, para la Banda 1 se recoge la mediana de los valores de la banda en el período, el valor máximo, el valor mínimo en el año y la amplitud de variación. Al final, cada píxel durante un año lleva hasta 156 capas de información.
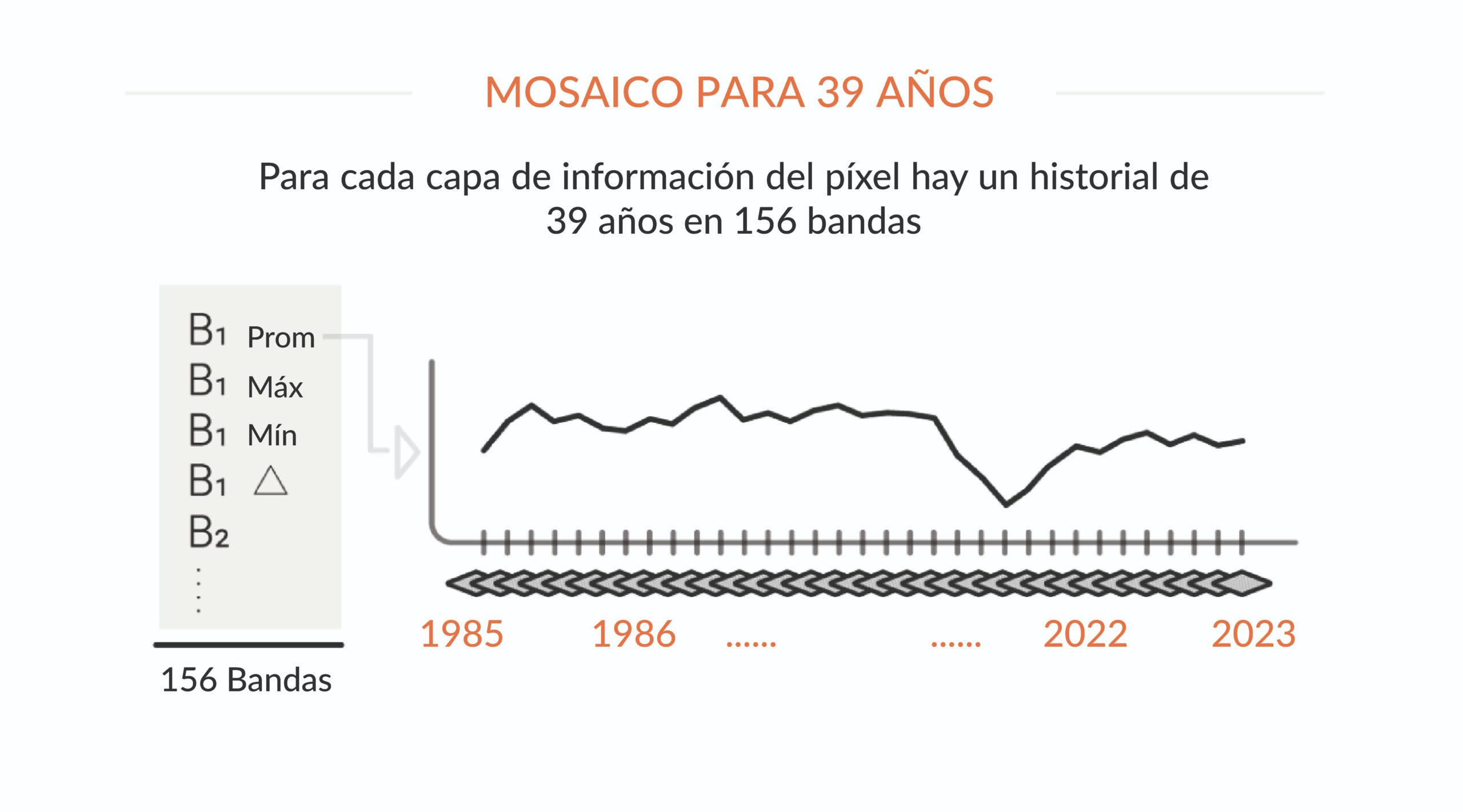
Para cada año se crean mosaicos que cubren toda RAISG, representando el comportamiento de cada píxel a través de 156 capas de información. Este conjunto de mosaicos se guarda como una colección de datos (ASSET) dentro de la plataforma Google Earth Engine. Estos mosaicos se utilizarán de dos formas principales: primero, como fuente de parámetros para el algoritmo de clasificación de las imágenes (ver siguiente paso), y segundo, como base para derivar la composición RGB, que permite la visualización de la imagen de fondo en la plataforma MapBiomas. Esta composición también se usa para la recolección de muestras de entrenamiento y evaluar la precisión mediante interpretación visual.
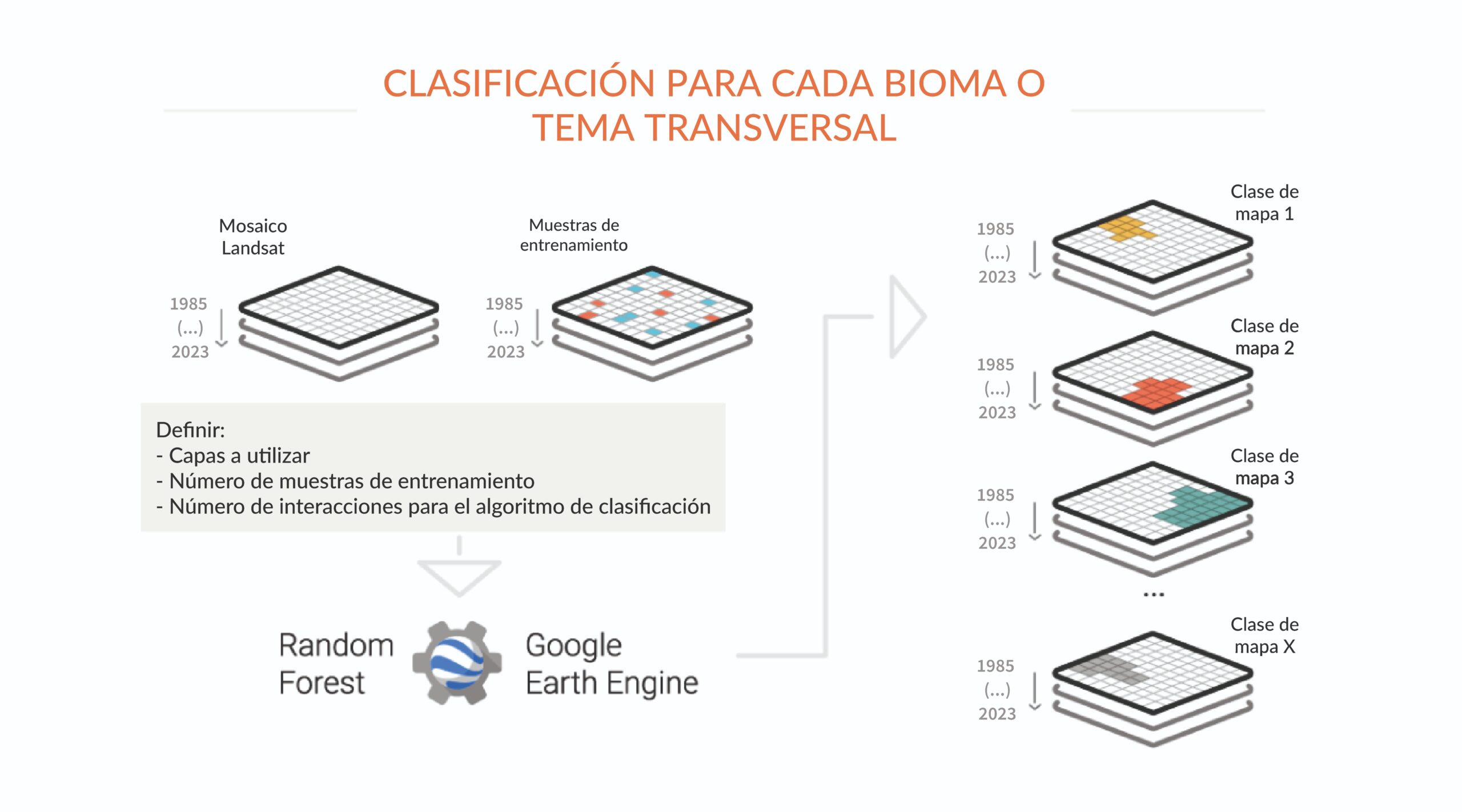
A partir de los mosaicos, los equipos de cada bioma y de cada tema transversal elaboran un mapa de cada clase de cobertura y uso del suelo (Bosque natural, Formación campestre, Agricultura, Pastos, Área urbana, Cuerpos de agua, etc.). Para ello, los analistas de MapBiomas utilizan un clasificador automático llamado “random forest”, el cual se ejecuta en la nube de procesadores de Google. Este sistema se basa en el aprendizaje automático: para cada tema a clasificar, las máquinas se “entrenan” con muestras de los objetivos a clasificar. Estas muestras se obtienen a través de mapas de referencia, generación de mapas de clases estables a partir de series anteriores de MapBiomas y por recolección directa por interpretación visual de imágenes Landsat. La clasificación se realiza cada uno de los años de la serie, y se puede guardar como un único mapa por clase donde cada píxel tiene un número de capas correspondiente al número de años de la serie histórica analizada.
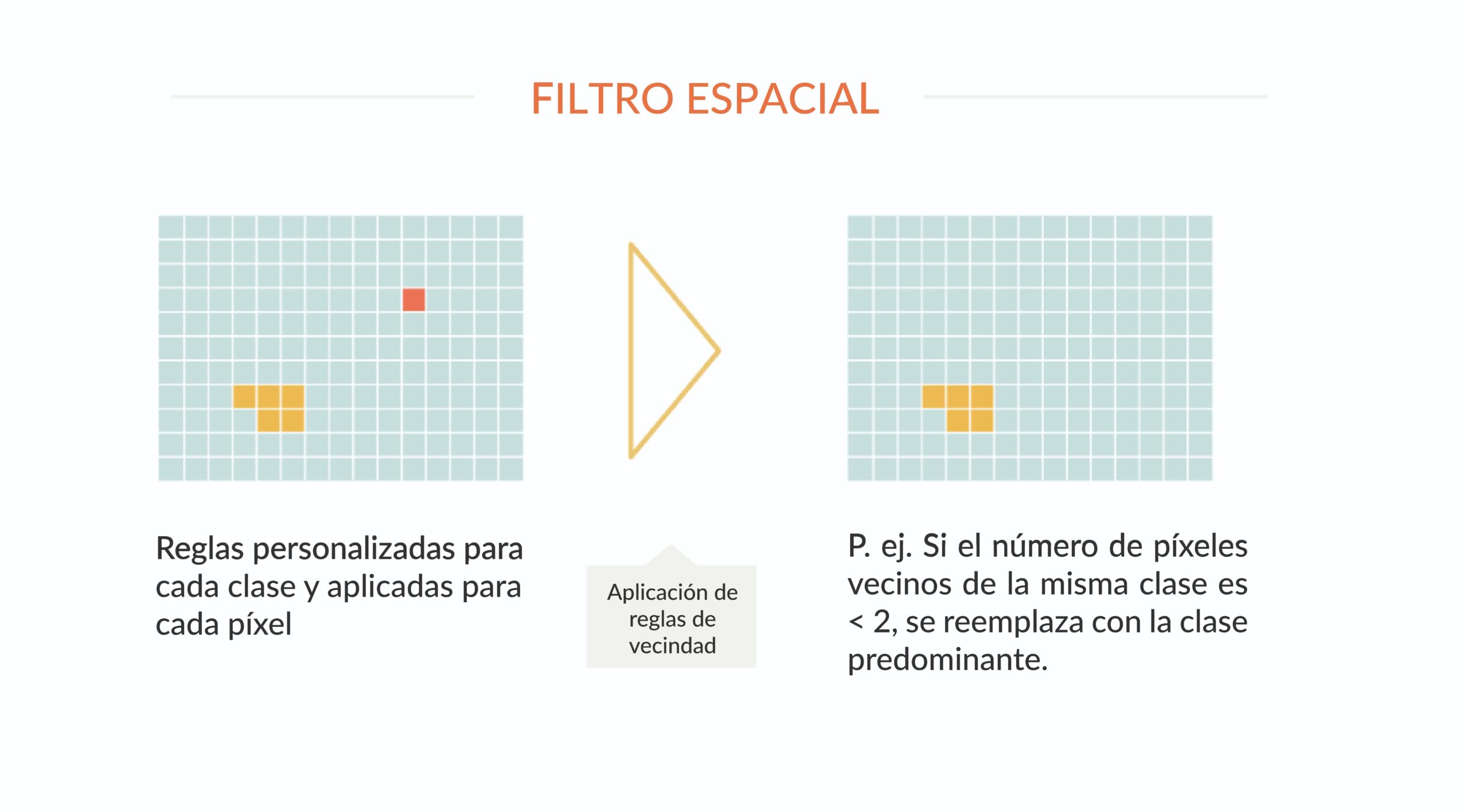
El filtro espacial tiene como objetivo aumentar la consistencia espacial de los datos, eliminando píxeles aislados o de borde. Se definen reglas de vecindad que pueden conducir a un cambio en la clasificación de píxeles. Por ejemplo, un píxel que tiene menos de dos de los nueve píxeles vecinos en la misma clase se reclasificará a la clase predominante en la vecindad. Cada píxel en cada año y para cada clase de uso pasa por este proceso de filtro espacial.
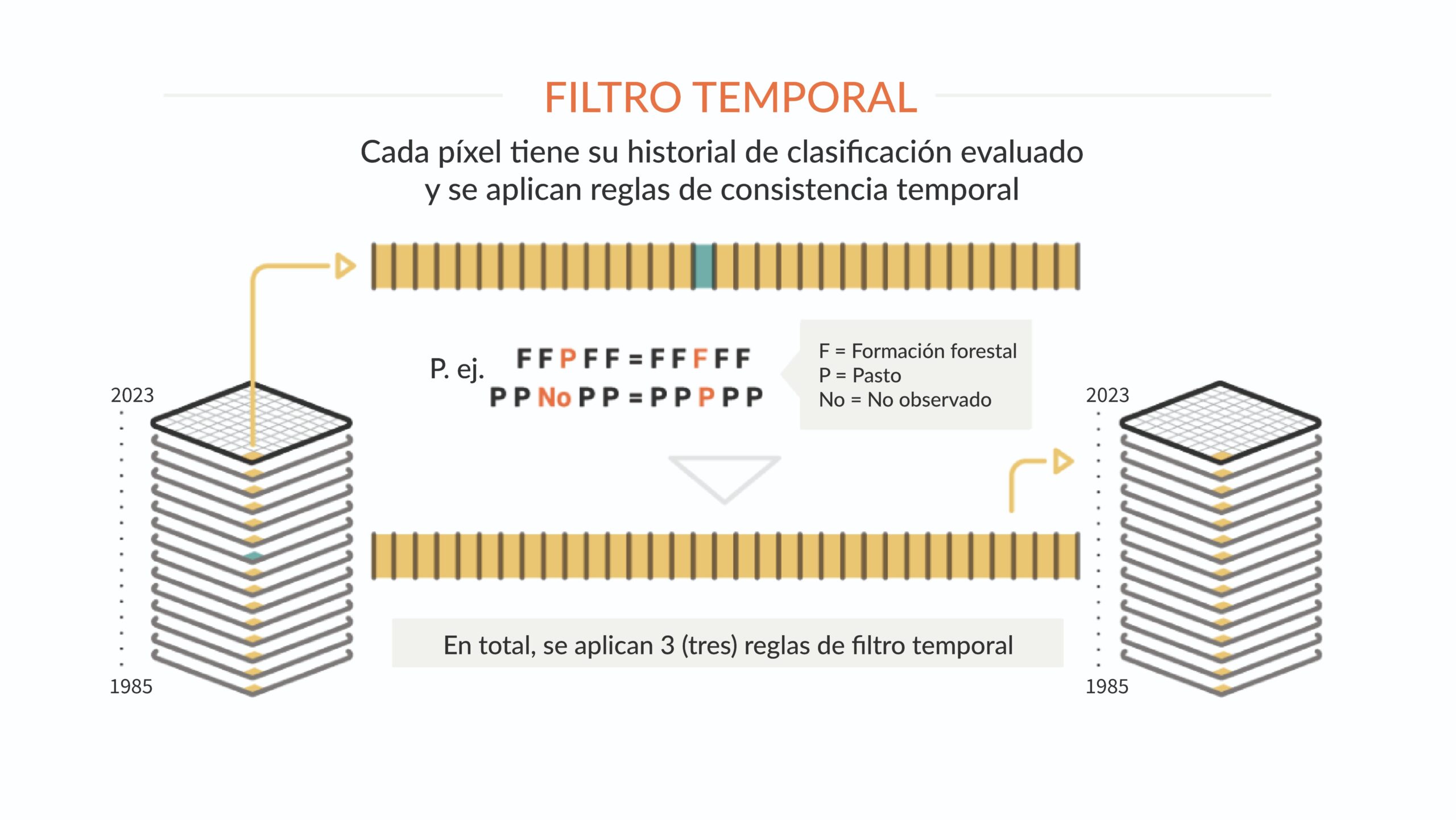
Para reducir las inconsistencias temporales, especialmente los cambios imposibles o no permitidos en la cobertura y el uso (por ejemplo, Bosque natural > No bosque > Bosque natural) y corregir las fallas debido al exceso de nubes o falta de datos, se aplican reglas de filtro temporal. Cada bioma, tema o región puede tener reglas de filtro temporal específicas. En total en la Colección 6 se aplicaron 3 reglas. El filtro temporal se aplica a cada píxel analizando todos los años de la Colección (39 años).
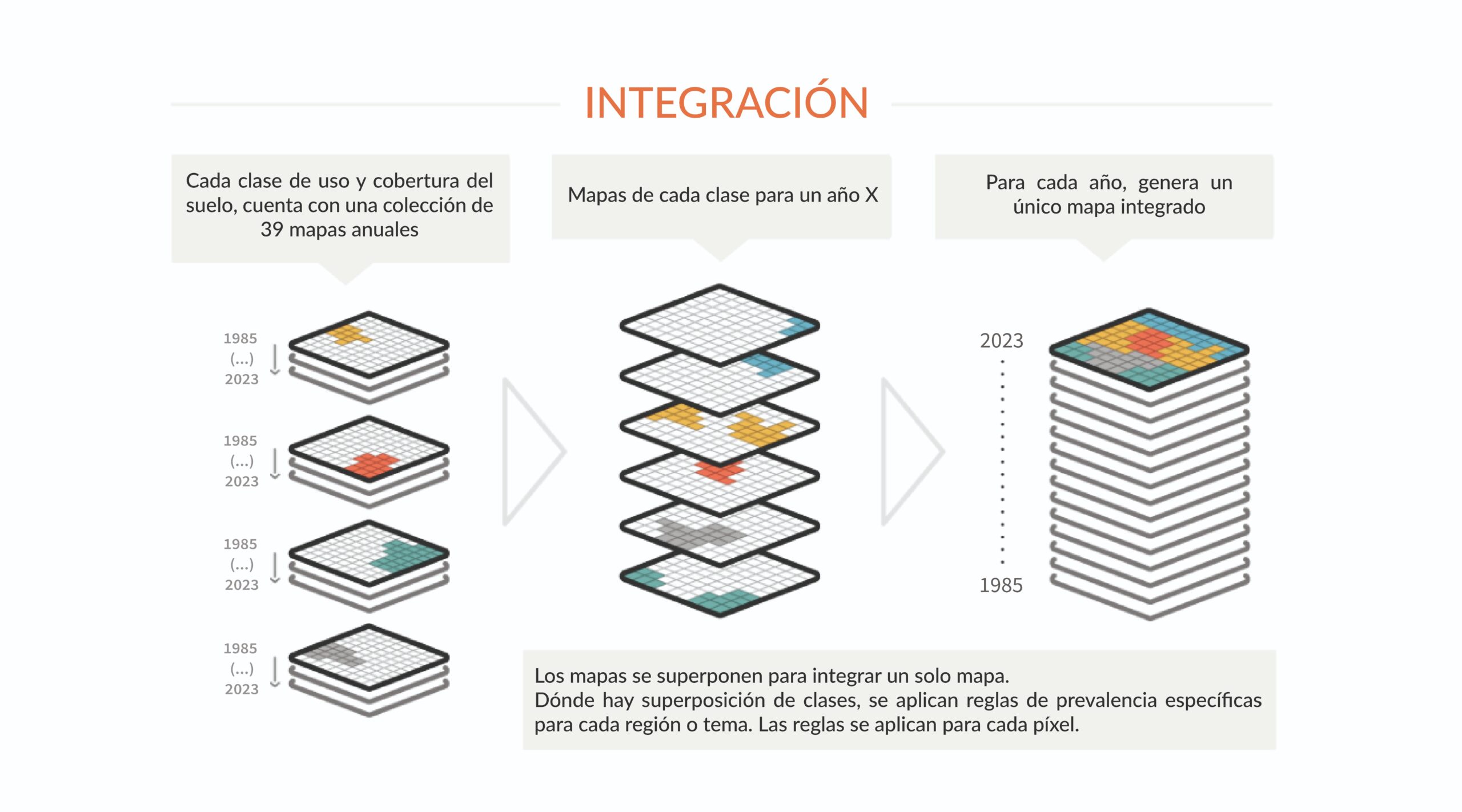
En este paso, los mapas de cada clase se integran en un solo mapa que representa la cobertura y uso de suelo de todo el territorio para cada año. Se aplican reglas de prevalencia: de esta manera, si un mismo píxel se clasifica en dos mapas de clases diferentes, es posible definir a cuál pertenece en el mapa final. Las reglas de prevalencia pueden variar según las peculiaridades de los biomas, temas o regiones. La integración se realiza para cada año de la serie y genera un mapa integrado para cada año, generalmente guardado como un único ASSET con el número de capas anuales del período analizado. El mapa integrado pasa por un paso más de filtro espacial para limpiar los bordes y los píxeles sueltos como resultado del proceso de integración.
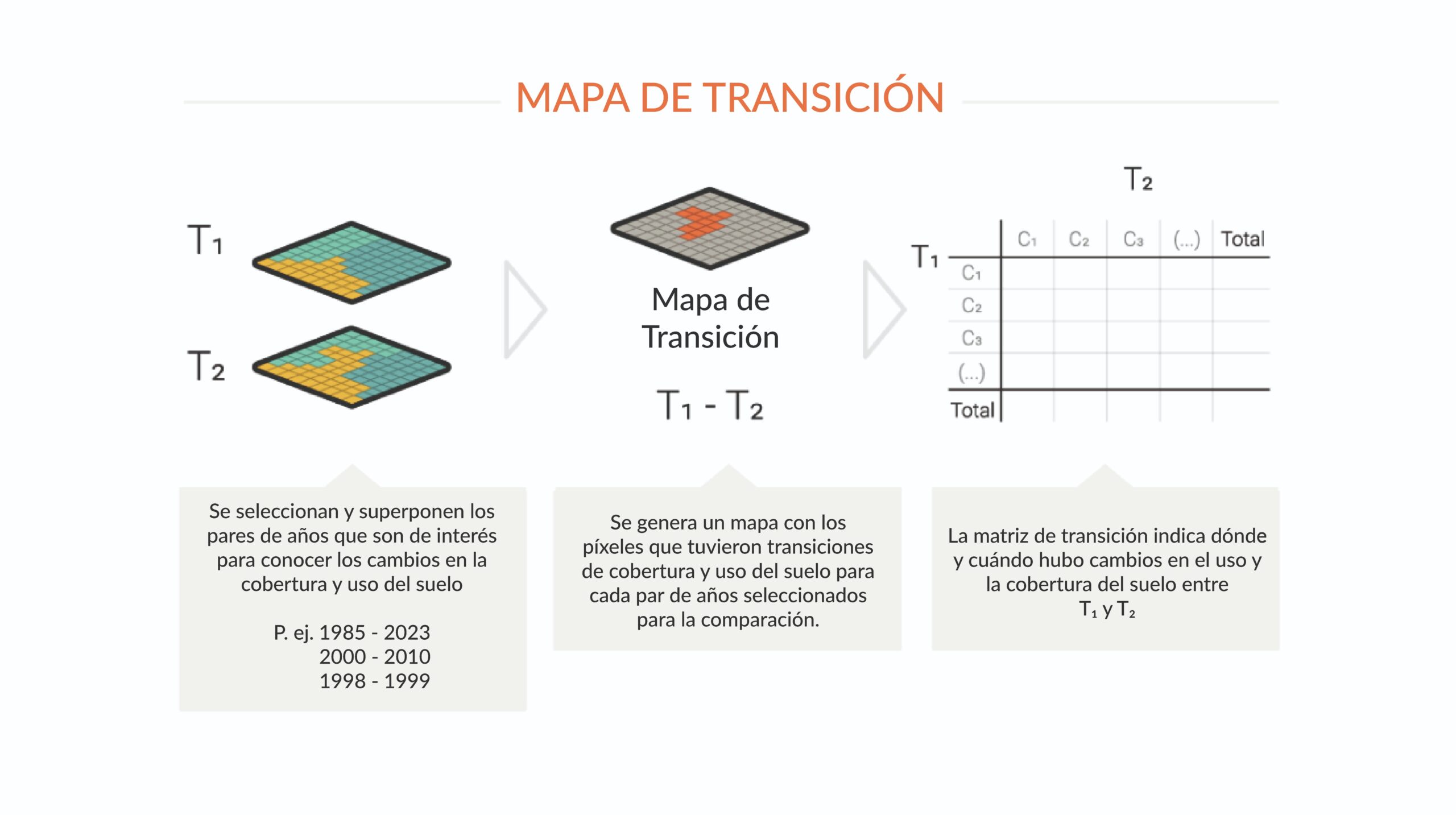
Para comprender los cambios en la cobertura y el uso del suelo, se producen mapas con transiciones de clase entre diferentes pares de años seleccionados. Así, es posible visualizar el dinamismo del territorio, y responder preguntas como cuánto del bosque se ha convertido en pasto de un año a otro, por ejemplo, entre otros cambios en el paisaje. Los mapas de transición se producen píxel a píxel y, una vez finalizados, también se someten a un filtro espacial para eliminar los píxeles de transición aislados o de borde. A partir de estos mapas se construyen matrices de transición para cada bioma, estado, municipio y demás tramos territoriales disponibles en la plataforma MapBiomas Amazonía.